

Centenas de milhões de anos de evolução abençoaram nosso planeta com uma grande variedade de formas de vida, cada uma inteligente à sua maneira. Cada espécie evoluiu para desenvolver habilidades distintas, capacidades de aprendizagem e uma forma física que garante sua sobrevivência em seu ambiente.
- Siga o tecflow no Google News!
- Participe do nosso grupo no Telegram ou Whatsapp2!
- Confira nossos stories no Instagram e veja notícias como essa!
- Siga o tecflow no Google Podcast e Spotify Podcast para ouvir nosso conteúdo!
- Anuncie conosco aqui.
Mas, apesar de ser inspirado pela natureza e evolução, o campo da inteligência artificial tem se concentrado em criar os elementos de inteligência separadamente e fundi-los após o desenvolvimento. Embora essa abordagem tenha dado ótimos resultados, também limitou a flexibilidade dos agentes de IA em algumas das habilidades básicas encontradas até mesmo nas formas de vida mais simples.
Em um novo artigo publicado na revista científica Nature, pesquisadores de IA da Universidade de Stanford apresentam uma nova técnica que pode ajudar a tomar medidas para superar alguns desses limites. Intitulada “Deep Evolutionary Reinforcement Learning”, a nova técnica utiliza um ambiente virtual complexo e um aprendizado reforçado para criar agentes virtuais que possam evoluir tanto em sua estrutura física quanto em capacidades de aprendizagem. Os achados podem ter implicações importantes para o futuro da pesquisa de IA e robótica.
Evolução é difícil de simular
Na natureza, corpo e cérebro evoluem juntos. Ao longo de muitas gerações, todas as espécies animais passaram por inúmeros ciclos de mutação para crescer membros, órgãos e um sistema nervoso para apoiar as funções de que precisa em seu ambiente. Mosquitos têm visão térmica para detectar calor corporal. Morcegos têm asas para voar e um aparelho de ecolocalização para navegar em lugares escuros. Tartarugas marinhas têm nadadeiras para nadar e um sistema de detecção de campo magnético para viajar longas distâncias. Os humanos têm uma postura vertical que liberta seus braços e permite que eles vejam o horizonte distante, mãos e dedos ágeis que podem manipular objetos, e um cérebro que os torna as criaturas mais sociais e nos capacita a encontrar soluções para resolver problemas.
Curiosamente, todas essas espécies descendem da primeira forma de vida que apareceu na Terra há vários bilhões de anos. Com base nas pressões de seleção causadas pelo meio ambiente, os descendentes desses primeiros seres vivos evoluíram em muitas direções diferentes.
Estudar a evolução da vida e da inteligência é interessante. Mas replicá-la é extremamente difícil. Um sistema de IA que pretende recriar a vida inteligente da mesma forma que a evolução teria que buscar muita informação, que é extremamente caro computacionalmente. Precisaria de muitos ciclos paralelos e sequenciais de tentativa e erro.
Os pesquisadores de IA usam vários atalhos e recursos pré-assinados para superar alguns desses desafios. Por exemplo, eles fixam a arquitetura ou o design físico de um sistema de IA ou robótico e se concentram em otimizar os parâmetros aprendeu. Outro atalho é o uso da evolução lamarckiana em vez da darwiniana, na qual os agentes de IA transmitem seus parâmetros aprendidos aos seus descendentes. Outra abordagem é treinar diferentes subsistemas de IA separadamente (visão, locomoção, linguagem, etc.) e, em seguida, afixá-los juntos em um sistema final de IA ou robótico. Embora essas abordagens acelerem o processo e reduzam os custos de treinamento e evolução dos agentes de IA, elas também limitam a flexibilidade e a variedade de resultados que podem ser alcançados.
Aprendizado de reforço
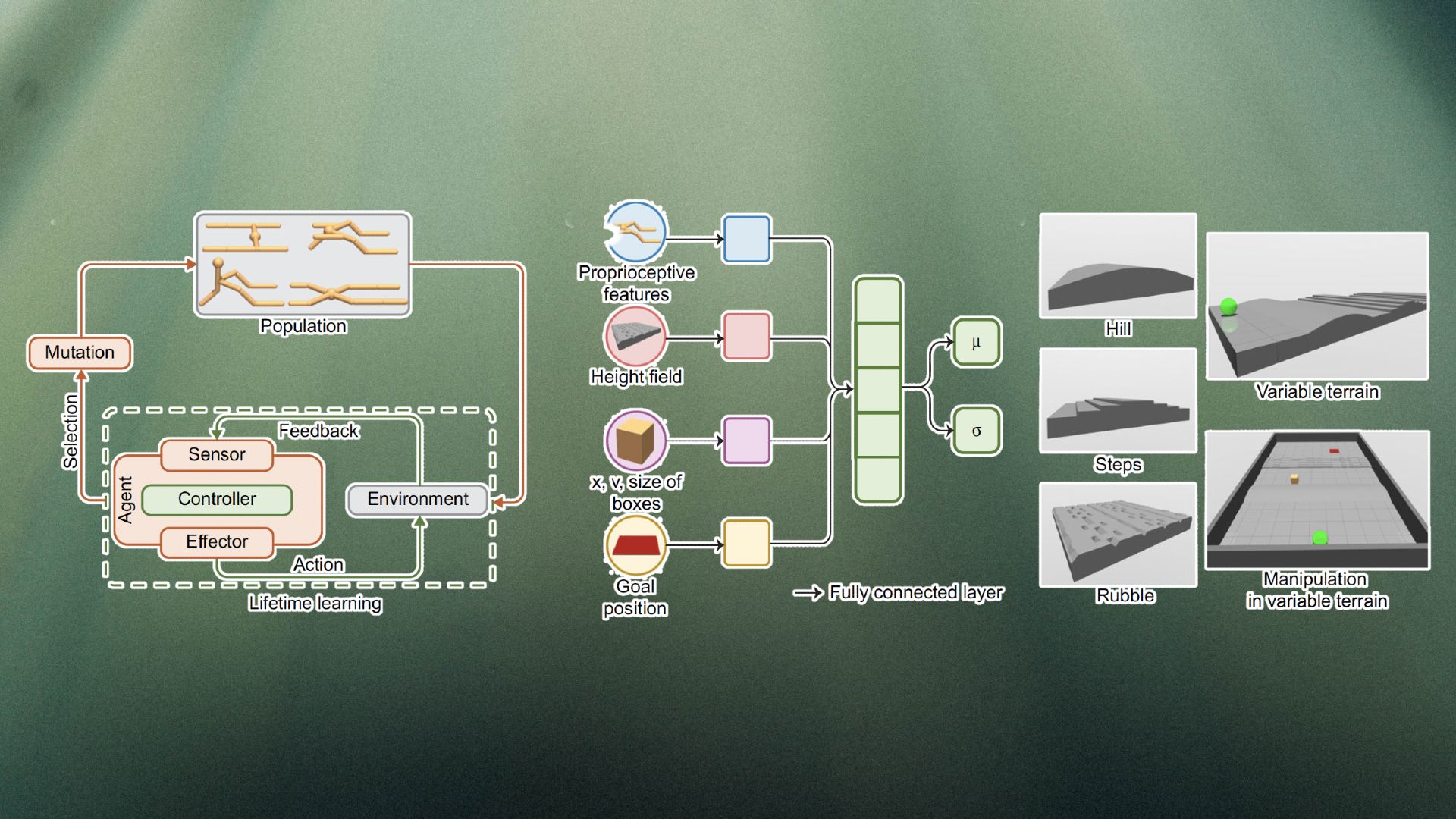
Em seu novo trabalho, os pesquisadores de Stanford pretendem aproximar a pesquisa de IA do processo evolutivo real, mantendo os custos o mais baixos possível.
“Nosso objetivo é elucidar alguns princípios que regem as relações entre a complexidade ambiental, a morfologia evoluída e a capacidade de aprendizado do controle inteligente”, escrevem em seu artigo.
Sua estrutura é chamada de Deep Evolutionary Reinforcement Learning. Na DERL, cada agente usa um aprendizado de reforço profundo para adquirir as habilidades necessárias para maximizar seus objetivos durante sua vida útil. A DERL usa a evolução darwiniana para procurar o espaço morfológico para soluções ideais, o que significa que quando uma nova geração de agentes de IA são gerados, eles só herdam os traços físicos e arquitetônicos de seus pais (juntamente com pequenas mutações). Nenhum dos parâmetros aprendidos são passados através de gerações.
“A DERL abre as portas para a realização de experimentos em larga escala para produzir insights científicos sobre como a aprendizagem e a evolução criam de forma cooperativa relações sofisticadas entre a complexidade ambiental, a inteligência morfológica e a aprendizagem das tarefas de controle”, escrevem os pesquisadores.
Simulando evolução da Inteligência Artificial
Para sua estrutura, os pesquisadores usaram o MuJoCo, um ambiente virtual que fornece simulação de física de corpo rígido altamente precisa. Seu espaço de design é chamado de AniMAL UNIversal (UNIMAL), no qual o objetivo é criar morfologias que aprendam tarefas de locomoção e manipulação de objetos em uma variedade de terrenos.
Cada agente no ambiente é composto por um genótipo que define seus membros e articulações. O descendente direto de cada agente herda o genótipo do pai e passa por mutações que podem criar novos membros, remover membros existentes ou fazer pequenas modificações em características como os graus de liberdade ou o tamanho dos membros.
Cada agente é treinado com aprendizado reforçado para maximizar recompensas em diversos ambientes. A tarefa mais básica é a locomoção, na qual o agente é recompensado pela distância que percorre durante um episódio. Agentes cuja estrutura física é mais adequada para atravessar terrenos aprendem mais rápido a usar seus membros para se locomover.
Para testar os resultados do sistema, os pesquisadores geraram agentes em três tipos de terrenos: plano (FT), variável (VT) e terrenos variáveis com objetos modificáveis (MVT). O terreno plano coloca a menor pressão de seleção sobre a morfologia dos agentes. Os terrenos variáveis, por outro lado, forçam os agentes a desenvolver uma estrutura física mais versátil que possa subir encostas e se mover em obstáculos. A variante MVT tem o desafio adicional de exigir que os agentes manipulem objetos para alcançar seus objetivos.
Os benefícios do DERL
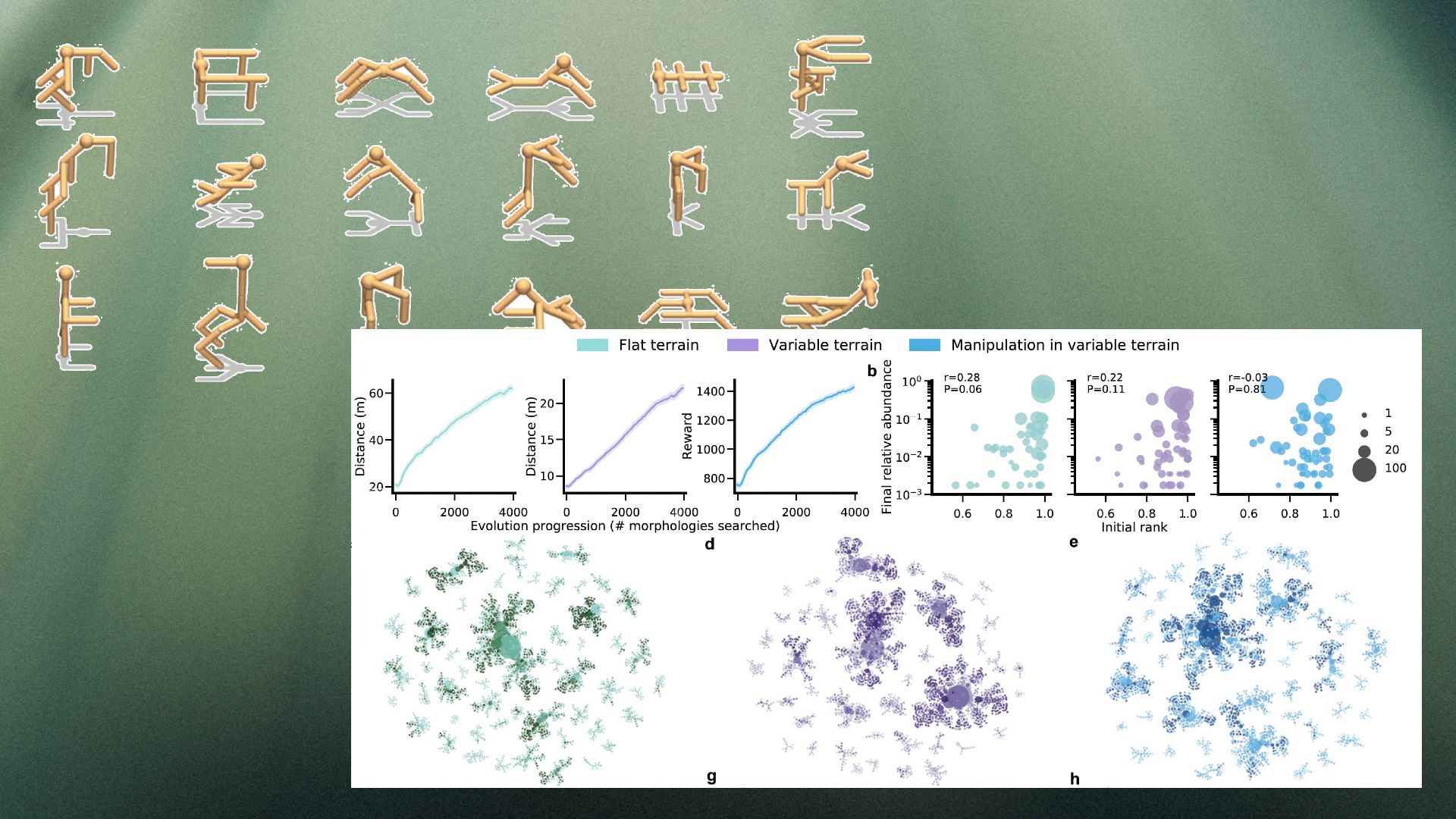
Um dos achados interessantes do DERL é a diversidade dos resultados. Outras abordagens para a IA evolutiva tendem a convergir em uma solução porque novos agentes herdam diretamente o físico e os aprendizados de seus pais. Mas no DERL, apenas dados morfológicos são passados aos descendentes, o sistema acaba criando um conjunto diversificado de morfologias bem sucedidas, incluindo bipeds, tripulos e quadrúpedes com e sem braços.
Ao mesmo tempo, o sistema mostra traços do efeito Baldwin,o que sugere que agentes que aprendem mais rápido são mais propensos a se reproduzir e passar seus genes para a próxima geração. A DERL mostra que a evolução “seleciona para alunos mais rápidos sem qualquer pressão de seleção direta para fazê-lo”, de acordo com o artigo de Stanford.
“Curiosamente, a existência desse efeito baldwin morfológico poderia ser explorada em estudos futuros para criar agentes incorporados com menor complexidade amostral e maior capacidade de generalização”, escrevem os pesquisadores.
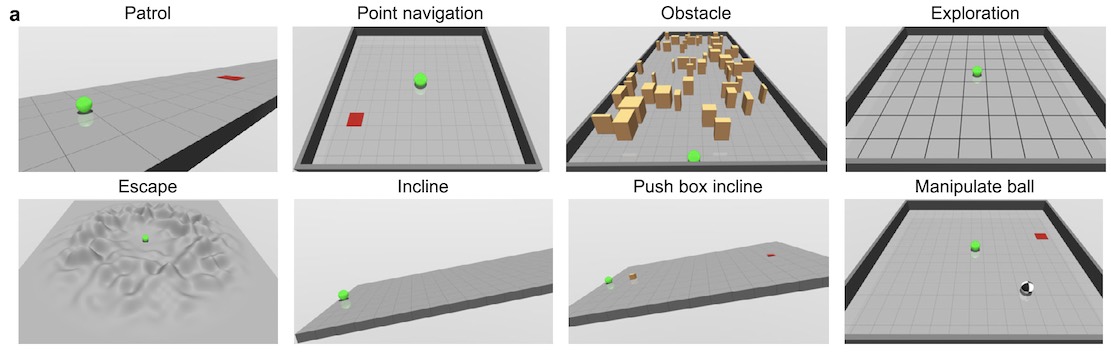
Por fim, o quadro DERL também valida a hipótese de que ambientes mais complexos darão origem a agentes mais inteligentes. Os pesquisadores testaram os agentes evoluídos em oito tarefas diferentes, incluindo patrulhamento, fuga, manipulação de objetos e exploração. Seus achados mostram que, em geral, os agentes que evoluíram em terrenos variáveis aprendem mais rápido e têm um desempenho melhor do que os agentes de IA que apenas experimentaram terreno plano.
Suas descobertas parecem estar em consonância com outra hipótese dos pesquisadores do DeepMind de que um ambiente complexo, uma estrutura de recompensa adequada e um aprendizado reforçado podem eventualmente levar ao surgimento de todos os tipos de comportamentos inteligentes.
Pesquisa de IA e robótica
O ambiente DERL só tem uma fração das complexidades do mundo real. “Embora o DERL nos permita dar um passo significativo na escala da complexidade dos ambientes evolutivos, uma importante linha de trabalho futuro envolverá a concepção de ambientes evolutivos mais abertos, fisicamente realistas e multi-agentes”, escrevem os pesquisadores.
No futuro, os pesquisadores expandirão o leque de tarefas de avaliação para avaliar melhor como os agentes podem melhorar sua capacidade de aprender comportamentos relevantes para o homem.
O trabalho pode ter implicações importantes para o futuro da IA e da robótica e pressionar os pesquisadores a usar métodos de exploração muito mais semelhantes à evolução natural.
“Esperamos que nosso trabalho incentive novas explorações em larga escala de aprendizado e evolução em outros contextos para produzir novas percepções científicas sobre o surgimento de comportamentos inteligentes rapidamente aprendeu, bem como novos avanços de engenharia em nossa capacidade de instanciar-los em máquinas”, escrevem os pesquisadores.
Este artigo foi originalmente publicado por Ben Dickson no TechTalks, uma publicação que examina tendências em tecnologia, como elas afetam a maneira como vivemos e fazemos negócios, e os problemas que eles resolvem. Mas também discutimos o lado maligno da tecnologia, as implicações mais sombrias da nova tecnologia, e o que precisamos olhar para fora. Você pode ler o artigo original aqui.
Faça como os mais de 4.000 leitores do tecflow, clique no sino azul e tenha nossas notícias em primeira mão!